CI/CD 开发指南
CI/CD pipelines 是 GitLab 开发和部署流程的基础部分,自动化了构建、测试和部署代码变更等任务。 在开发与 pipelines 交互或触发的功能时,必须考虑这些操作对系统安全性和运行完整性的广泛影响。
本文档提供指导,帮助您安全有效地开发使用 CI/CD pipelines 的功能。 它强调了理解运行 pipelines 的重要性、负责任地管理认证令牌,以及在开发过程初期就集成安全考虑。
通用指南
- 将 pipelines 视为写操作:触发 pipeline 是一种改变系统状态的写操作。该操作可以启动部署、运行测试或修改配置。将 pipeline 视与其他关键写操作一样谨慎处理,以防止未授权的更改或系统滥用。
- 运行 pipeline 应该是明确的操作:在用户上下文中创建 pipeline 的操作应设计为,当执行该操作时,用户明确知道会启动一个 pipeline(或单个 job)。用户应该在 pipeline 执行的之前就了解其中执行的变更。
- 远程执行和隔离:CI/CD pipeline 作为远程执行环境运行,其中 jobs 可以执行执行各种操作的脚本。确保 jobs 得到充分隔离,不会意外暴露敏感数据或系统。
- 与应用安全(AppSec)和验证(Verify)团队协作:在设计过程和起草提案时尽早包含 Application Security (AppSec) 和 Verify 团队成员。他们的专业知识可以帮助识别潜在的安全风险,并确保安全考虑从一开始就集成到功能中。此外,让他们参与代码审查过程,以利用他们在识别漏洞和确保符合安全标准方面的专业知识。
- 确定 pipeline 执行者:在构建触发 pipelines 的功能时,必须考虑哪个用户启动了 pipeline。您需要确定谁应该是事件的执行者。这是用户直接触发 pipeline 的有意运行(例如通过推送更改到仓库或点击"运行 pipeline"按钮),还是由 GitLab 系统或策略启动的 pipeline 运行? 避免创建 pipeline 的用户不是更改作者的场景。如果用户不同,存在更改作者可以在 pipeline 用户上下文中运行代码的风险。 了解执行者有助于管理权限并确保 pipeline 在正确的执行上下文中运行。
- job 执行用户的可变性:运行特定 job 的用户可能与创建 pipeline 的用户不同。虽然在大多数情况下用户是相同的,但也存在 job 用户变化的场景,例如运行手动 job 或重试 job。这种可变性会影响 job 执行上下文中的权限和访问级别。在使用 CI/CD job token (
CI_JOB_TOKEN) 开发功能时,始终要考虑这种可能性。考虑 job 用户是否应该更改以及操作的执行者是谁。 - 限制操作范围:为与 CI/CD job token 一起使用启用新端点时,强烈建议将操作限制在同一 job、pipeline 或项目范围内以增强安全性。强烈建议选择较小的范围(job)而非较大的范围(项目)。例如,如果允许访问 pipeline 数据,请将其限制在当前 pipeline 以防止跨项目或跨 pipeline 的数据暴露。评估跨项目或跨 pipeline 访问是否真正必要;限制范围可以降低安全风险。
- 监控和审计活动:确保功能可审计且可监控。引入会触发 pipeline 事件的详细日志,包括 pipeline 用户、启动操作的执行者和事件详情。
其他指南
特定于 CI/CD 的开发指南在此列出:
- 如果您正在创建新的 CI/CD 模板,请阅读 GitLab CI/CD 模板的开发指南。
- 如果您正在添加新关键字或修改 CI schema,请参考以下指南:
- 如果您正在修改核心 CI/CD 流程(如 linting 或 pipeline 创建),请参考 CI/CD 测试指南
请参阅 CI/CD YAML 参考文档指南 了解如何更新 CI/CD YAML 语法参考页面。
指标
本节描述了工程师在开发、变更验证和事件调查期间可以使用的仪表板和指标。
- 所有 GitLab 团队的仪表板可在此处获取 here。 您可以搜索您感兴趣的功能类别所属的团队。
- Pipeline 执行错误预算仪表板 包含关于 pipeline 创建和 job 执行的其他有用指标。
- 生产日志 也提供许多可在 Kibana 中搜索和聚合的有用信息。
- Pipeline 创建仪表板 提供了 pipeline 创建过程中涉及步骤的有用分解。 请注意,此仪表板仅包含"慢速 pipelines"的数据,即创建时间较长或包含许多 jobs 的 pipelines。 它类似于 SQL 的"慢查询日志"。
- CI 分区仪表板 包含关于当前分区号、分区大小、清理和其他数据库指标的信息。
CI/CD 使用示例
我们维护了一个 ci-sample-projects 组,其中包含展示
不同 GitLab CI/CD 用例的 .gitlab-ci.yml 示例的项目。它们还涵盖了可用于不同场景的特定语法。
CI 架构概述
以下是 CI 架构的简化图示。为专注于主要组件,省略了一些细节。
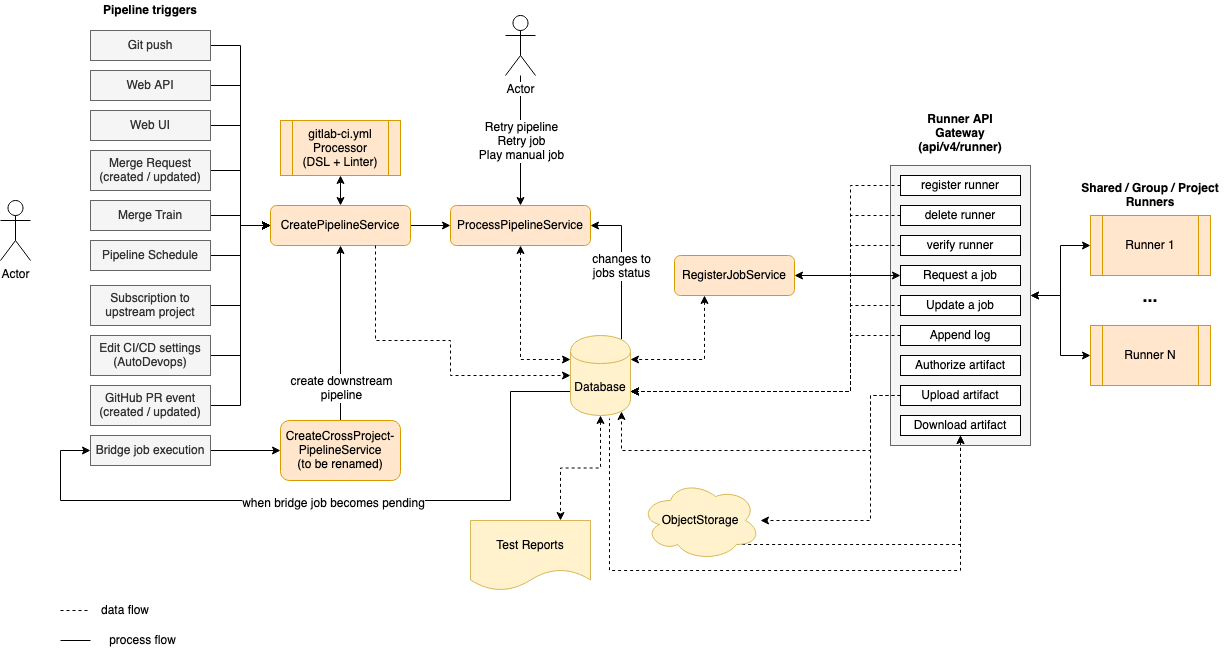
左侧是可基于各种事件(由用户或自动化触发)触发 pipeline 的事件:
git push是最常见的触发 pipeline 的事件。- Web API。
- 用户在 UI 中选择"运行 pipeline"按钮。
- 当 merge request 被创建或更新时。
- 当 MR 被添加到 Merge Train 时。
- 定时 pipeline。
- 当项目 订阅上游项目时。
- 当启用 Auto DevOps 时。
- 当使用 GitHub 集成处理 外部 pull requests 时。
- 当上游 pipeline 包含一个触发下游 pipeline 的 bridge job 时。
触发任何这些事件都会调用 CreatePipelineService,
它接收事件数据和触发它的用户作为输入,然后尝试创建一个 pipeline。
CreatePipelineService 严重依赖 YAML Processor 组件,
该组件负责接收 YAML blob 作为输入并返回 pipeline 的抽象数据结构(包括 stages 和所有 jobs)。此组件在处理 YAML 时还验证其结构,
并返回任何语法或语义错误。YAML Processor 组件是我们定义
所有可用关键字 来构建 pipeline 的地方。
CreatePipelineService 接收 YAML Processor 返回的抽象数据结构,
然后将其转换为持久化模型(如 pipeline、stages 和 jobs)。之后,pipeline 就准备好进行处理。
处理 pipeline 意味着按执行顺序(stage 或 needs)运行 jobs,
直到以下任一情况发生:
- 所有预期的 jobs 都已执行。
- 失败中断了 pipeline 执行。
处理 pipeline 的组件是 ProcessPipelineService,
它负责将 pipeline 的所有 jobs 移动到完成状态。当 pipeline 创建时,其所有 jobs 最初都处于 created 状态。
此服务查看哪些处于 created 阶段的 jobs 基于 pipeline 结构有资格被处理。
然后将它们移动到 pending 状态,这意味着它们现在可以被 runner 选取。
job 执行完成后可以成功或失败。pipeline 中每个 job 的状态转换都会再次触发此服务,
它会查找下一个要向完成状态转换的 jobs。在此过程中,ProcessPipelineService
会更新 jobs、stages 和整个 pipeline 的状态。
图表右侧是连接到 GitLab 实例的 runners 列表。
这些可以是实例 runners、组 runners 或项目 runners。
runners 和 Rails 服务器之间的通信通过一组 API 端点进行,这些端点分组为
Runner API Gateway。
我们可以注册、删除和验证 runners,这也会导致对数据库的读写查询。runner 连接后,
它会持续请求下一个要执行的 job。这会调用 RegisterJobService,
它选取下一个 job 并将其分配给 runner。此时 job 转换为 running 状态,
由于状态变化再次触发 ProcessPipelineService。
更多详细信息请阅读 Job 调度。
当 job 正在执行时,runner 会将日志以及任何需要存储的工件发送回服务器。 此外,job 可能依赖于之前 jobs 的工件才能运行。在这种情况下, runner 使用专用的 API 端点下载它们。
工件存储在对象存储中,而元数据保存在数据库中。 工件的重要示例是报告(如 JUnit、SAST 和 DAST),这些报告在 merge request 中被解析和渲染。
job 状态转换并非都是自动化的。用户可以运行 手动 jobs、取消 pipeline、
重试特定的失败 jobs 或整个 pipeline。任何导致 job 状态变更的操作都会触发 ProcessPipelineService,
因为它负责跟踪整个 pipeline 的状态。
一种特殊类型的 job 是 bridge job,它在转换为 pending 状态时在服务器端执行。
此 job 负责创建下游 pipeline,如多项目 pipeline 或子 pipeline。
每次触发下游 pipeline 时,工作流程循环都会从 CreatePipelineService 重新开始。
您可以在 CI 后端架构演练 中观看架构演练视频。
Job 调度
当 Pipeline 创建时,其所有 jobs 都会立即为所有 stages 创建,初始状态为 created。
这使得可视化 pipeline 的完整内容成为可能。
处于 created 状态的 job 尚未被 runner 看到。为了将 job 分配给 runner,
job 必须首先转换为 pending 状态,这可能在以下情况下发生:
- job 在 pipeline 的第一个阶段创建。
- job 需要手动启动并且已被触发。
- 前一个 stage 的所有 jobs 已成功完成。在这种情况下,我们将下一个 stage 的所有 jobs 转换为
pending。 - job 使用
needs:指定了依赖关系,并且所有依赖的 jobs 都已完成。 - job 由于其不可运行状态没有被 丢弃,这是由于
Ci::PipelineCreation::DropNotRunnableBuildsService。
当 runner 连接时,它会通过持续轮询服务器来请求下一个要运行的 pending job。
runner 用来与 GitLab 交互的 API 端点定义在 lib/api/ci/runner.rb 中
服务器收到请求后,基于 Ci::RegisterJobService 算法 选择一个 pending job,
然后将其分配并发送给 runner。
当前 stage 的所有 jobs 完成后,服务器通过将下一个 stage 的所有 jobs 状态更改为 pending 来"解锁"它们。
这些 jobs 现在可以在 runner 请求新 jobs 时被调度算法选取,并如此继续直到所有 stages 完成。
runner 与 GitLab 服务器之间的通信
runner 使用注册令牌 注册 后,服务器就知道它可以执行哪种类型的 jobs。 这取决于:
- 注册的 runner 类型:
- 实例 runner
- 组 runner
- 项目 runner
- 任何关联的标签。
runner 通过使用 POST /api/v4/jobs/request 请求要执行的 jobs 来发起通信。
尽管轮询每隔几秒发生一次,但如果 job 队列没有变化,我们利用 HTTP 头部缓存来减少服务器端的工作负载。
此 API 端点运行 Ci::RegisterJobService,它:
- 从
pendingjobs 池中选取下一个要运行的 job - 将其分配给 runner
- 通过 API 响应将其呈现给 runner
Ci::RegisterJobService
此服务使用 3 个顶级查询来收集大多数 jobs,它们根据 runner 注册的级别进行选择:
- 为实例 runner 选取 jobs(实例范围)
- 使用公平调度算法,优先运行较少的 projects
- 为组 runner 选取 jobs
- 为项目 runner 选取 jobs
然后通过匹配 job 和 runner 标签进一步过滤此 jobs 列表。
如果 job 包含标签,runner 如果不匹配所有标签就不会选取该 job。 runner 可能拥有比 job 定义更多的标签,但不能相反。
最后,如果 runner 只能选取标记的 jobs,所有未标记的 jobs 都会被过滤掉。
此时我们循环遍历剩余的 pending jobs,并尝试根据额外策略分配 runner"可以选取"的第一个 job。
例如,标记为 protected 的 runners 只能运行针对受保护分支(如生产部署)的 jobs。
随着池中 runners 数量的增加,我们也会增加冲突的可能性,这些冲突如果将同一个 job 分配给不同的 runners 就会发生。 为防止这种情况,我们优雅地处理冲突错误并分配列表中的下一个 job。
丢弃卡住的 builds
有两种方式可以将 builds 标记为"卡住"并丢弃它们。
- 当 build 创建时,
Ci::PipelineCreation::DropNotRunnableBuildsService检查已知的 upfront 条件,这些条件会使 jobs 无法执行:- 如果没有足够的 CI/CD Minutes 来运行 build,则立即丢弃该 build 并标记为
ci_quota_exceeded。 - 将来,如果项目不在可用 runners 通过
allowed_plans要求的计划上,则立即丢弃该 build 并标记为no_matching_runner。
- 如果没有足够的 CI/CD Minutes 来运行 build,则立即丢弃该 build 并标记为
- 如果没有可用的 Runner 来选取 build,它会在 1 小时后被
Ci::StuckBuilds::DropPendingService丢弃。- 如果 job 在 24 小时内没有被 runner 选取,它会在该时间后自动从处理队列中移除。
- 如果 pending job 是卡住的,当没有可用的 runner 能处理它时,它会在 1 小时后从队列中移除。
- 在这两种情况下,job 的状态都会更改为
failed并带有适当的失败原因。
这种差异背后的原因
计算分钟配额机制在 job 创建时早期处理,因为对于大多数时间来说这是一个恒定的决策。 一旦项目超过限制,每个匹配的下一个 job 都将适用,直到下个月开始。 当然,项目所有者可以购买额外的分钟数,但这是项目需要采取的手动操作。
相同的机制将很快用于 allowed_plans soon。
如果项目不在所需计划上,并且 job 针对这样的 runner,
它将不断失败,直到项目所有者更改配置或将命名空间升级到所需计划。
这两种机制也非常特定于 SaaS,同时当我们考虑 SaaS 的规模时,计算成本也很高。 在 job 甚至转换为 pending 之前进行检查并早期失败在这里很有意义。
为什么我们不处理其他情况并在早期丢弃 pending jobs? 在某些情况下,job 处于 pending 状态只是因为 runner 在接收 jobs 时速度慢。 这不是 GitLab 级别可以知道的。 根据 runner 的配置和容量以及 GitLab 中队列的大小,job 可能被立即接收,或者可能需要等待。
可能还有其他原因:
- 您正在处理 runner 维护,它在一段时间内完全不可用,
- 您正在更新配置,并且错误地搞乱了标记和/或受保护标志(或者在 SaaS 实例 runners 的情况下;您分配了错误的价格因子或
allowed_plans配置)。
所有这些都是可能只是暂时的、大多不被期望发生且预期会被早期检测和修复的问题。 我们绝对不希望在发生这些条件之一时立即丢弃 jobs。 仅仅因为 runner 容量不足或存在暂时的不可用/配置错误就丢弃 job 会对用户造成很大伤害。
GitLab CI/CD 中"Job"的定义
GitLab CI 上下文中的"Job"指的是驱动持续集成、交付和部署的任务。 通常,一个 pipeline 包含多个 stages,一个 stage 包含多个 jobs。
在 Active Record 建模中,Job 被定义为 CommitStatus 类。
在此基础上,我们有以下类型的 jobs:
Ci::Build… 要由 runners 执行的 job。Ci::Bridge… 触发下游 pipeline 的 job。GenericCommitStatus… 在外部 CI/CD 系统中执行的 job,例如 Jenkins。
当您在代码库中使用"Job"术语时,读者会认为该类/对象是上述任何类型。
如果您特指 Ci::Build 类,您不应将该对象/类命名为"job",因为这可能会造成一些混淆。
在文档中,我们应该使用通用的"Job",而不是"Build"。
我们的代码库中存在一些不一致之处,应该进行重构。
例如,CommitStatus 应该是 Ci::Job,而 Ci::JobArtifact 应该是 Ci::BuildArtifact。
完整的重构计划请参阅 此问题。
计算配额
此图显示了 计算配额 功能及其组件的工作原理。
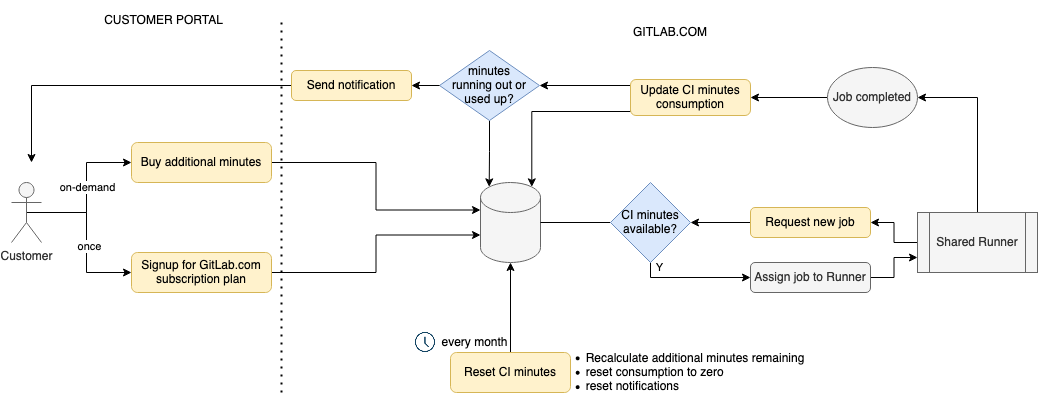
在下面的视频中观看此功能的详细演练。