批量迭代表格
Rails 提供了一个名为 in_batches 的方法,可用于按批次迭代数据行。例如:
User.in_batches(of: 10) do |relation|
relation.update_all(updated_at: Time.now)
end遗憾的是,该方法的实现方式在查询效率和内存使用方面效率不高。
为此,您可以将 EachBatch 模块包含到模型中,然后使用 each_batch 类方法。例如:
class User < ActiveRecord::Base
include EachBatch
end
User.each_batch(of: 10) do |relation|
relation.update_all(updated_at: Time.now)
end这将生成如下查询:
User Load (0.7ms) SELECT "users"."id" FROM "users" WHERE ("users"."id" >= 41654) ORDER BY "users"."id" ASC LIMIT 1 OFFSET 1000
(0.7ms) SELECT COUNT(*) FROM "users" WHERE ("users"."id" >= 41654) AND ("users"."id" < 42687)该方法的 API 与 in_batches 类似,但不支持 in_batches 的所有参数。除非您有特定需求使用 in_batches,否则应始终使用 each_batch。
非唯一列的迭代
不应在非唯一列(在关系上下文中)上使用 each_batch 方法,因为这可能导致无限循环。此外,当迭代非唯一列时,不一致的批次大小会导致性能问题。即使您在迭代属性时应用最大批次大小,也无法保证生成的批次不超过该大小。以下代码片段演示了这种情况:当尝试选择 id 在 1 到 10,000 之间的用户的 Ci::Build 条目时,数据库返回 1 215 178 匹配行。
[ gstg ] production> Ci::Build.where(user_id: (1..10_000)).size
=> 1215178这是因为构建的关系被转换为以下查询:
[ gstg ] production> puts Ci::Build.where(user_id: (1..10_000)).to_sql
SELECT "ci_builds".* FROM "ci_builds" WHERE "ci_builds"."type" = 'Ci::Build' AND "ci_builds"."user_id" BETWEEN 1 AND 10000
=> nil通过范围 WHERE "ci_builds"."user_id" BETWEEN ? AND ? 过滤非唯一列的 And 查询,即使范围大小限制在特定阈值(如前例中的 10,000),该阈值也不会转换为返回数据集的大小。这是因为当获取属性可能的 n 个值时,无法确定包含这些值的记录数量是否小于 n。
使用 distinct_each_batch 进行松散索引扫描
当必须迭代非唯一列时,使用 distinct_each_batch 辅助方法。该方法利用松散索引扫描技术(跳过索引扫描)跳过数据库索引中的重复值。
示例:在 Issue 模型中迭代不同的 author_id:
Issue.distinct_each_batch(column: :author_id, of: 1000) do |relation|
users = User.where(id: relation.select(:author_id)).to_a
end该技术能确保批次间性能稳定,无论数据分布如何。relation 对象返回一个 ActiveRecord 作用域,其中仅包含指定的 column,其他列不会被加载。
底层数据库查询使用递归 CTE,会增加额外开销。因此建议使用比标准 each_batch 迭代更小的批次大小。
列定义
EachBatch 默认使用模型的主键进行迭代。这在大多数情况下有效,但有时您可能希望使用其他列进行迭代。
Project.distinct.each_batch(column: :creator_id, of: 10) do |relation|
puts User.where(id: relation.select(:creator_id)).map(&:id)
end上述查询迭代项目创建者并打印其 ID,避免重复。
如果列不是唯一的(无唯一索引定义),则必须在关系上调用 distinct 方法。在不使用 distinct 的情况下使用非唯一列可能导致 each_batch 陷入无限循环,如以下问题所述。
数据迁移中的 EachBatch
处理数据迁移时,迭代大量数据的推荐方式是使用 EachBatch。
数据迁移的特殊情况是批量后台迁移,其中实际的数据修改在后台作业中执行。确定数据范围(切片)并调度后台作业的迁移代码使用 each_batch。
高效使用 each_batch
EachBatch 有助于迭代大型表格。需要强调的是,EachBatch 并不能神奇地解决所有迭代相关的性能问题,在某些场景下可能完全无效。从数据库角度看,正确配置的数据库索引也是使 EachBatch 高效运行的必要条件。
示例 1:简单迭代
假设我们要迭代 users 表并将 User 记录打印到标准输出。该表包含数百万条记录,因此运行单个查询获取用户很可能超时。
以下是简化版的 users 表,包含几行数据。我们在 id 列中设置了一些小间隙,使示例更真实(部分记录已被删除)。id 字段上存在一个索引:
ID |
sign_in_count |
created_at |
|---|---|---|
1 |
1 |
2020-01-01 |
2 |
4 |
2020-01-01 |
9 |
1 |
2020-01-03 |
300 |
5 |
2020-01-03 |
301 |
9 |
2020-01-03 |
302 |
8 |
2020-01-03 |
303 |
2 |
2020-01-03 |
350 |
1 |
2020-01-03 |
351 |
3 |
2020-01-04 |
352 |
0 |
2020-01-05 |
353 |
9 |
2020-01-11 |
354 |
3 |
2020-01-12 |
将所有用户加载到内存中(应避免):
users = User.all
users.each { |user| puts user.inspect }使用 each_batch:
# 注意:本示例选择 5 作为批次大小,默认为 1_000
User.each_batch(of: 5) do |relation|
relation.each { |user| puts user.inspect }
endeach_batch 的工作原理
首先,通过执行以下数据库查询找到表中最小的 id(起始 id):
SELECT "users"."id" FROM "users" ORDER BY "users"."id" ASC LIMIT 1
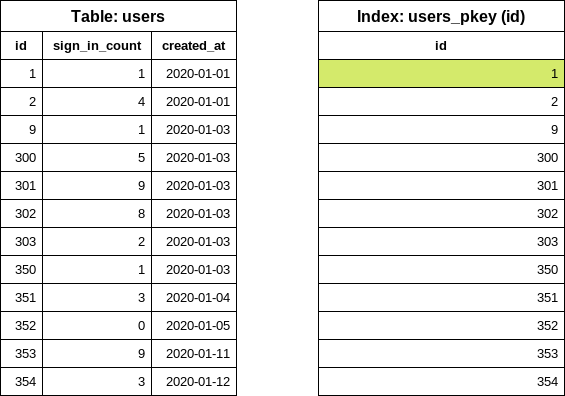
注意查询仅从索引读取数据(INDEX ONLY SCAN),未访问表。数据库索引已排序,因此取出第一项是成本极低的操作。
下一步是找到下一个 id(结束 id),需遵循批次大小配置。本例中批次大小为 5。EachBatch 使用 OFFSET 子句获取“偏移”的 id 值:
SELECT "users"."id" FROM "users" WHERE "users"."id" >= 1 ORDER BY "users"."id" ASC LIMIT 1 OFFSET 5
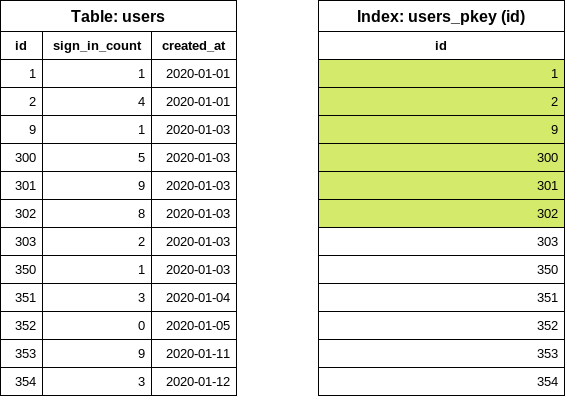
同样,查询仅检查索引。OFFSET 5 取出第六个 id 值:无论表大小或迭代次数如何,该查询最多从索引读取六项。
此时,我们已知第一个批次的 id 范围。现在是为 relation 块构建查询的时候:
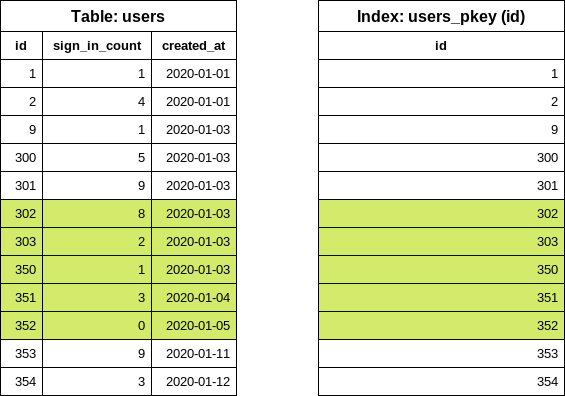
SELECT "users".* FROM "users" WHERE "users"."id" >= 1 AND "users"."id" < 302
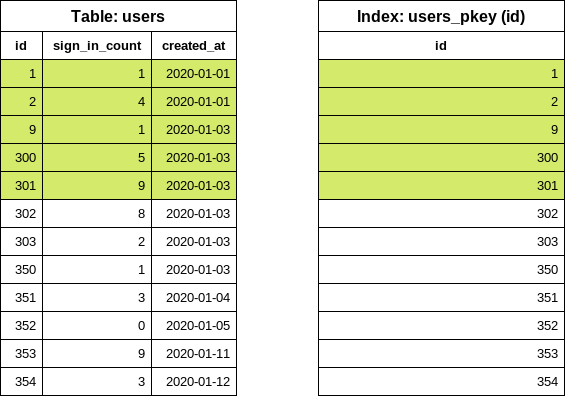
注意 < 符号。之前从索引读取了六项,此查询中最后一项被“排除”。查询通过索引获取磁盘上五个 user 行的位置,并从表中读取这些行。返回的数组在 Ruby 中处理。
第一次迭代完成。对于下一次迭代,重用上一次迭代的最后一个 id 值来查找下一个结束 id 值:
SELECT "users"."id" FROM "users" WHERE "users"."id" >= 302 ORDER BY "users"."id" ASC LIMIT 1 OFFSET 5
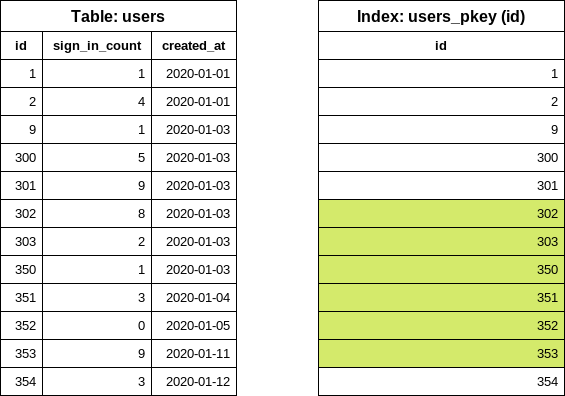
现在可以轻松构建第二次迭代的 users 查询:
SELECT "users".* FROM "users" WHERE "users"."id" >= 302 AND "users"."id" < 353
示例 2:带过滤的迭代
基于前一个示例,我们希望打印零登录次数的用户。我们在 sign_in_count 列中跟踪登录次数,因此编写以下代码:
users = User.where(sign_in_count: 0)
users.each_batch(of: 5) do |relation|
relation.each { |user| puts user.inspect }
endeach_batch 为起始 id 值生成以下 SQL 查询:
SELECT "users"."id" FROM "users" WHERE "users"."sign_in_count" = 0 ORDER BY "users"."id" ASC LIMIT 1仅选择 id 列并按 id 排序会强制数据库使用 id(主键索引)列上的索引,但我们还有对 sign_in_count 列的额外条件。该列不在索引中,因此数据库需要查看实际表以找到第一个匹配行。
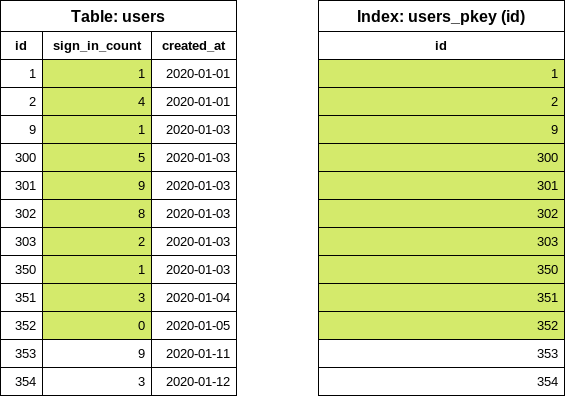
扫描的行数取决于表中的数据分布。
- 最佳情况:第一个用户从未登录。数据库仅读取一行。
- 最坏情况:所有用户至少登录过一次。数据库读取所有行。
在此特定示例中,数据库必须读取 10 行(无论我们的批次大小设置如何)才能确定第一个 id 值。在“真实世界”应用中,很难预测过滤是否会导致问题。对于 GitLab,在生产副本上验证数据是一个好的起点,但请记住 GitLab.com 上的数据分布可能与 GitLab 自托管实例不同。
使用 each_batch 改进过滤
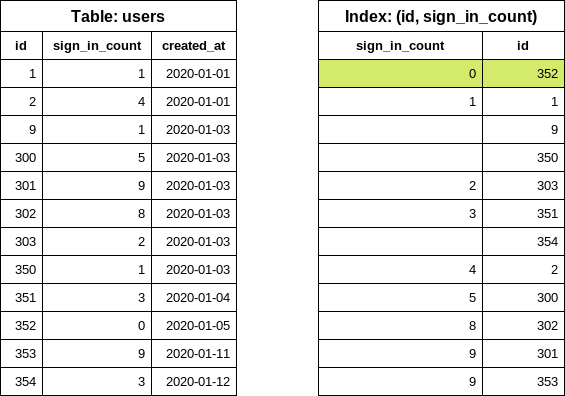
专用条件索引
CREATE INDEX index_on_users_never_logged_in ON users (id) WHERE sign_in_count = 0这是我们的表和新创建的索引的样子:
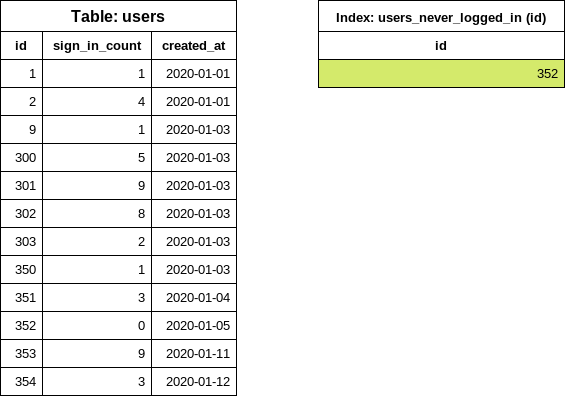 此索引定义涵盖了
此索引定义涵盖了 id 和 sign_in_count 列的条件,使 each_batch 查询非常高效(类似于简单迭代示例)。
用户从未登录的情况很少见,因此我们预期索引体积较小。在索引定义中仅包含 id 也有助于保持索引体积小。
列上的索引
稍后,我们可能希望迭代表并过滤不同的 sign_in_count 值,在这些情况下,我们无法使用之前建议的条件索引,因为 WHERE 条件与我们的新过滤器(sign_in_count > 10)不匹配。
为解决此问题,我们有两个选项:
- 创建另一个条件索引以覆盖新查询。
- 用更通用的配置替换索引。
在同一个表和相同列上拥有多个索引可能会在写入数据时成为性能瓶颈。
考虑以下索引(应避免):
CREATE INDEX index_on_users_never_logged_in ON users (id, sign_in_count)索引定义以 id 列开头,从数据选择性的角度来看使索引非常低效:
SELECT "users"."id" FROM "users" WHERE "users"."sign_in_count" = 0 ORDER BY "users"."id" ASC LIMIT 1执行上述查询会导致 INDEX ONLY SCAN。但查询仍需要迭代索引中未知数量的条目,然后找到第一个 sign_in_count 为 0 的项。
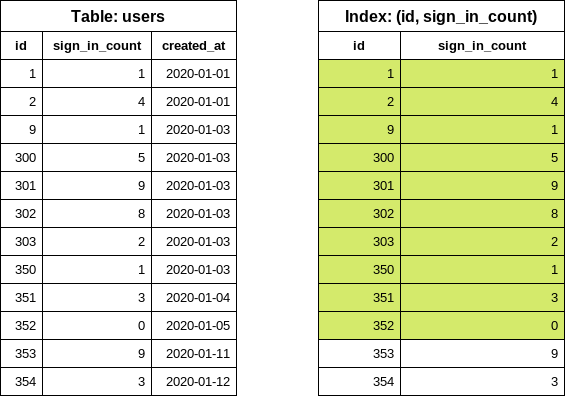
我们可以通过交换索引定义中的列来显著改进查询(推荐):
CREATE INDEX index_on_users_never_logged_in ON users (sign_in_count, id)
 以下索引定义不适用于
以下索引定义不适用于 each_batch(应避免):
CREATE INDEX index_on_users_never_logged_in ON users (sign_in_count)由于 each_batch 基于 id 列构建范围查询,此索引无法高效使用。数据库从表中读取行或使用位图搜索,同时读取主键索引。
“慢速”迭代
慢速迭代意味着我们使用良好的索引配置迭代表,并在生成的 relation 上应用过滤:
User.each_batch(of: 5) do |relation|
relation.where(sign_in_count: 0).each { |user| puts user.inspect }
end迭代使用主键索引(在 id 列上),使其免于语句超时。过滤器(sign_in_count: 0)应用于 relation,其中 id 已受约束(范围)。行数有限。
慢速迭代通常需要更长时间完成。迭代次数更高,一次迭代可能产生的记录少于批次大小。迭代甚至可能产生 0 条记录。这不是最佳解决方案;但在某些情况下(尤其是处理大型表时),这是唯一可行的选项。
使用子查询
在 each_batch 查询中使用子查询在大多数情况下效果不佳。考虑以下示例:
projects = Project.where(creator_id: Issue.where(confidential: true).select(:author_id))
projects.each_batch do |relation|
# do something
end迭代使用 projects 表的 id 列。分批不影响子查询。这意味着每次迭代时,数据库都会执行子查询。这为查询增加了恒定的“负载”,通常导致语句超时。我们不知道保密问题的数量,执行时间和访问的数据库行数取决于 issues 表中的数据分布。
仅当子查询返回少量行时,使用子查询才有效。
改进子查询
处理子查询时,慢速迭代方法可能有效:对 creator_id 的过滤可以成为生成的 relation 对象的一部分。
projects = Project.all
projects.each_batch do |relation|
relation.where(creator_id: Issue.where(confidential: true).select(:author_id))
end如果 issues 表本身的查询性能不够,可以构建嵌套循环。尽可能避免:
projects = Project.all
projects.each_batch do |relation|
issues = Issue.where(confidential: true)
issues.each_batch do |issues_relation|
relation.where(creator_id: issues_relation.select(:author_id))
end
end如果我们知道 issues 表比 projects 表有更多行,翻转查询顺序(先分批 issues 表)会更合理。
使用 JOIN 和 EXISTS
何时使用 JOINS:
- 当表之间存在 1:1 或 1:N 关系,且我们知道连接的记录(几乎)总是存在时。这适用于“扩展式”表:
projects-project_settingsusers-user_detailsusers-user_statuses
LEFT JOIN在此情况下效果良好。连接表上的条件需要放入生成的relation中,以便迭代不受连接表数据分布的影响。
示例:
User.each_batch do |relation|
relation
.joins("LEFT JOIN personal_access_tokens on personal_access_tokens.user_id = users.id")
.where("personal_access_tokens.name = 'name'")
endEXISTS 查询应仅添加到 each_batch 查询的内部 relation 中:
User.each_batch do |relation|
relation.where("EXISTS (SELECT 1 FROM ...")
end关系对象上的复杂查询
当 relation 对象有多个额外条件时,执行计划可能变得“不稳定”。
示例:
Issue.each_batch do |relation|
relation
.joins(:metrics)
.joins(:merge_requests_closing_issues)
.where("id IN (SELECT ...)")
.where(confidential: true)
end我们期望 relation 查询读取 BATCH_SIZE 条用户记录,然后根据提供的查询过滤结果。优化器可能决定使用 confidential 列上的索引进行位图索引查找是更好的执行方式。这可能导致读取意外大量的行,并导致查询超时。
问题:我们确定 relation 最多返回 BATCH_SIZE 条记录,但优化器不知道这一点。
使用公共表表达式(CTE)技巧强制范围查询优先执行:
Issue.each_batch(of: 1000) do |relation|
cte = Gitlab::SQL::CTE.new(:batched_relation, relation.limit(1000))
scope = cte
.apply_to(Issue.all)
.joins(:metrics)
.joins(:merge_requests_closing_issues)
.where("id IN (SELECT ...)")
.where(confidential: true)
puts scope.to_a
end计算记录数
对于包含大量数据的表,通过查询计算记录数可能导致超时。EachBatch 模块提供了一种替代方法来迭代计算记录。使用 each_batch 的缺点是在生成的 relation 对象上执行额外的计数查询。
each_batch_count 方法是一种更高效的方法,消除了额外计数查询的需要。通过调用此方法,迭代过程可以根据需要暂停和恢复。此功能在 Sidekiq 工作器中执行计数操作并在五分钟后触发错误预算违规的情况下特别有用。
举例来说,使用 EachBatch 计算记录涉及调用额外的计数查询,如下所示:
count = 0
Issue.each_batch do |relation|
count += relation.count
end
puts count另一方面,each_batch_count 方法使计数过程能够更高效地执行(计数是迭代查询的一部分),而无需调用额外的计数查询:
count, _last_value = Issue.each_batch_count # 此处可忽略 last_value此外,each_batch_count 方法允许计数过程随时暂停和恢复。以下代码片段演示了此功能:
stop_at = Time.current + 3.minutes
count, last_value = Issue.each_batch_count do
stop_at.past? # 停止计数的条件
end
# 稍后继续计数
stop_at = Time.current + 3.minutes
count, last_value = Issue.each_batch_count(last_count: count, last_value: last_value) do
stop_at.past?
endEachBatch vs BatchCount
当为 Service Ping 添加新计数器时,记录计数的推荐方式是使用 Gitlab::Database::BatchCount 类。BatchCount 中实现的迭代逻辑与 EachBatch 具有相似的性能特征。上述提到的改进 BatchCount 的大部分技巧和建议同样适用于 BatchCount。
使用键集分页进行迭代
在某些特殊情况下,使用 EachBatch 进行迭代无效。EachBatch 需要一个不同的列(通常是主键),这使得对时间戳列和复合主键表的迭代成为不可能。
在 EachBatch 不适用的情况下,您可以使用键集分页来迭代表或行范围。其扩展性和性能特性与 EachBatch 非常相似。
示例:
- 按特定顺序(时间戳列)迭代表,并结合使用决胜列(tie-breaker),如果用于排序的列不包含唯一值。
- 迭代具有复合主键的表。
按创建日期迭代项目中的问题
您可以使用键集分页按特定顺序迭代任何数据库列(例如 created_at DESC)。为确保具有相同 created_at 值的返回记录顺序一致,请使用具有唯一值的决胜列(例如 id)。
假设 issues 表中有以下索引:
idx_issues_on_project_id_and_created_at_and_id" btree (project_id, created_at, id)获取记录进行进一步处理
以下代码片段使用指定顺序(created_at, id)迭代项目中的问题记录:
scope = Issue.where(project_id: 278964).order(:created_at, :id) # id 是决胜列
iterator = Gitlab::Pagination::Keyset::Iterator.new(scope: scope)
iterator.each_batch(of: 100) do |records|
puts records.map(&:id)
end您可以为查询添加额外过滤器。此示例仅列出过去 30 天内创建的问题 ID:
scope = Issue.where(project_id: 278964).where('created_at > ?', 30.days.ago).order(:created_at, :id) # id 是决胜列
iterator = Gitlab::Pagination::Keyset::Iterator.new(scope: scope)
iterator.each_batch(of: 100) do |records|
puts records.map(&:id)
end批量更新记录
对于复杂的 ActiveRecord 查询,.update_all 方法效果不佳,因为它会生成不正确的 UPDATE 语句。您可以使用原始 SQL 批量更新记录:
scope = Issue.where(project_id: 278964).order(:created_at, :id) # id 是决胜列
iterator = Gitlab::Pagination::Keyset::Iterator.new(scope: scope)
iterator.each_batch(of: 100) do |records|
ApplicationRecord.connection.execute("UPDATE issues SET updated_at=NOW() WHERE issues.id in (#{records.dup.reselect(:id).to_sql})")
end为保持迭代稳定和可预测,请避免更新 ORDER BY 子句中的列。
迭代 merge_request_diff_commits 表
merge_request_diff_commits 表使用复合主键(merge_request_diff_id, relative_order),这使得 EachBatch 无法高效使用。
要对 merge_request_diff_commits 表进行分页,可以使用以下代码片段:
# 自定义顺序对象配置:
order = Gitlab::Pagination::Keyset::Order.build([
Gitlab::Pagination::Keyset::ColumnOrderDefinition.new(
attribute_name: 'merge_request_diff_id',
order_expression: MergeRequestDiffCommit.arel_table[:merge_request_diff_id].asc,
nullable: :not_nullable
),
Gitlab::Pagination::Keyset::ColumnOrderDefinition.new(
attribute_name: 'relative_order',
order_expression: MergeRequestDiffCommit.arel_table[:relative_order].asc,
nullable: :not_nullable
)
])
MergeRequestDiffCommit.include(FromUnion) # 键集分页生成 UNION 查询
scope = MergeRequestDiffCommit.order(order)
iterator = Gitlab::Pagination::Keyset::Iterator.new(scope: scope)
iterator.each_batch(of: 100) do |records|
puts records.map { |record| [record.merge_request_diff_id, record.relative_order] }.inspect
end顺序对象配置
键集分页适用于简单的 ActiveRecord order 作用域(第一个示例)。但在特殊情况下,您需要描述 ORDER BY 子句中的列(第二个示例),供底层键集分页库使用。当键集分页库无法自动确定 ORDER BY 配置时,会引发错误。
Gitlab::Pagination::Keyset::Order 和 Gitlab::Pagination::Keyset::ColumnOrderDefinition 类的代码注释概述了配置 ORDER BY 子句的可能选项。您也可以在键集分页文档中找到一些代码示例。