Geo (development)
Geo 将多个 GitLab 实例连接在一起。一个 GitLab 实例被指定为 primary 站点,可以运行多个 secondary 站点。Geo 协调了许多组件,这些组件可以在下面的图中看到,并在本文档中更详细地描述。
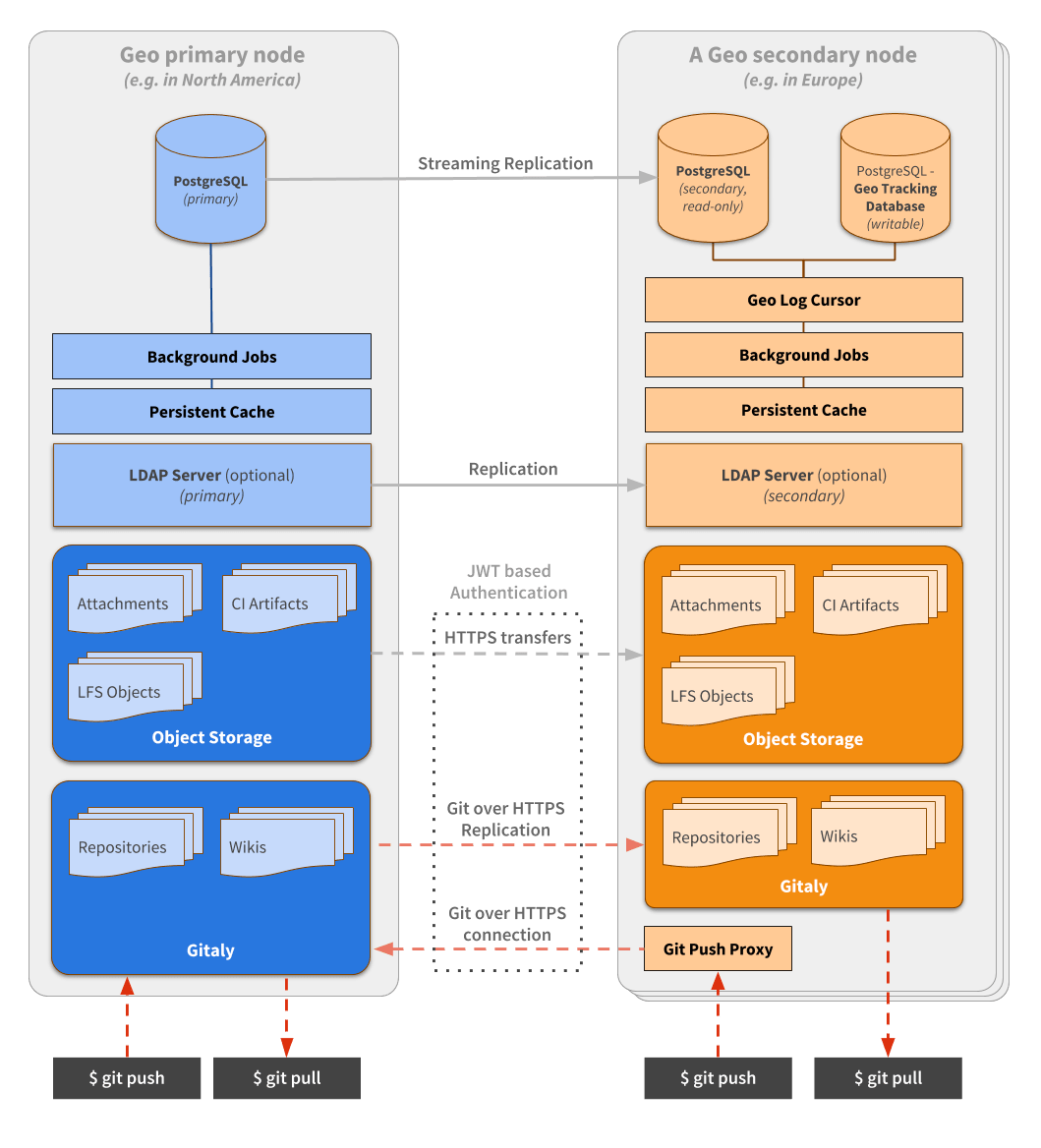
复制层
Geo 处理不同组件的复制:
- Database:包括整个应用程序,不包括缓存和作业。
- Git repositories:包括项目和 Wiki。
- Blobs:包括从问题附件到原始日志和 CI 资产的所有内容。
除了数据库复制外,在 secondary 站点上,所有内容都由 Geo Log Cursor 协调。
复制状态
下图说明了复制的工作原理。为清晰起见,省略了一些允许的转换。
stateDiagram-v2
Pending --> Started
Started --> Synced
Started --> Failed
Synced --> Pending: Mark for resync
Failed --> Pending: Mark for resync
Failed --> Started: Retry
Geo Log Cursor 守护进程
Geo Log Cursor 守护进程 是在每个 secondary 站点上运行的独立进程。它监控 Geo Event Log 中的新事件,并为每种特定事件类型创建后台作业。
例如,当仓库被更新时,Geo primary 站点创建一个包含关联仓库更新事件的 Geo 事件。Geo Log Cursor 守护进程获取该事件并调度一个 Geo::ProjectSyncWorker 作业,该作业使用 Geo::RepositorySyncService 来更新仓库。
Geo Log Cursor 守护进程可以自动在 High Availability 模式下运行。守护进程定期尝试获取锁,一旦获取,它就作为 active 守护进程运行。
同一站点上任何其他运行的守护进程都处于备用模式,准备在 active 守护进程释放其锁时恢复工作。
我们使用 ExclusiveLease 锁类型,带有小的 TTL,在每个轮询周期中续期。这使我们能够实现具有超时的全局锁。
在轮询周期结束时,如果守护进程无法续期和/或重新获取锁,它会切换到备用模式。
数据库复制
Geo 使用 streaming replication 将数据库从 primary 复制到 secondary 站点。这种复制使 secondary 站点能够访问数据库中保存的所有数据,因此用户可以登录到 secondary 站点并读取所有问题和合并请求。
仓库复制
Geo 还复制仓库。每个 secondary 站点跟踪 tracking database 中每个仓库的状态。
仓库通过以下几种方式被复制:
项目仓库注册表
Geo::ProjectRepositoryRegistry 类定义了用于跟踪仓库复制状态的模型。对于主数据库中的每个项目,跟踪数据库中保留一条记录。
它记录关于仓库的以下信息:
- 它们上次同步的时间。
- 它们上次成功同步的时间。
- 它们是否需要重新同步。
- 应该何时重试。
- 重试次数。
- 它们是否以及何时被验证。
它还为项目 Wiki 在专用列中存储这些属性。
仓库注册表同步工作进程
Geo::RepositoryRegistrySyncWorker 类在后台定期运行,它搜索 Geo::ProjectRepositoryRegistry 模型中需要更新的项目。这些项目可以是:
- 未同步的:从未在 secondary 站点上同步过的项目,因此尚不存在。
- 最近更新的:具有比
Geo::ProjectRepositoryRegistry模型中的last_repository_successful_sync_at时间戳更新的last_repository_updated_at时间戳的项目。 - 手动:管理员可以在 Geo Admin 区域 中手动标记仓库进行重新同步。
当我们在 secondary 上尝试获取仓库 RETRIES_BEFORE_REDOWNLOAD 次失败后,Geo 会执行所谓的 re-download。它将干净地克隆到存储根目录下的 @geo-temporary 目录中。成功后,我们用新克隆的仓库替换主仓库。
Blob 复制
诸如 uploads、LFS 对象和 CI 作业工件等 Blob,通过 Self-Service Framework 复制到 secondary 站点。为了跟踪同步状态,每个模型都有一个对应的注册表表,例如 Upload 在 PostgreSQL Geo Tracking Database 中有 Geo::UploadRegistry。
服务之间的 Blob 复制正常路径工作流
下图使用作业工件作为 Blob 的一个示例。
复制新的作业工件
Primary 站点:
sequenceDiagram participant R as Runner participant P as Puma participant DB as PostgreSQL participant SsP as Secondary site PostgreSQL R->>P: Upload artifact P->>DB: Insert `ci_job_artifacts` row P->>DB: Insert `geo_events` row P->>DB: Insert `geo_event_log` row DB->>SsP: Replicate rows
- Runner 上传一个工件
- Puma 插入
ci_job_artifacts行 - Puma 插入
geo_events行,包含"ID 为 123 的作业工件已更新"之类的数据 - Puma 插入指向
geo_events行的geo_event_log行(因为我们在一些遗留逻辑之上构建了 SSF) - PostgreSQL 流式复制在只读副本中插入这些行
Secondary 站点,在 PostgreSQL DB 行被复制后:
sequenceDiagram participant DB as PostgreSQL participant GLC as Geo Log Cursor participant R as Redis participant S as Sidekiq participant TDB as PostgreSQL Tracking DB participant PP as Primary site Puma GLC->>DB: Query `geo_event_log` GLC->>DB: Query `geo_events` GLC->>R: Enqueue `Geo::EventWorker` S->>R: Pick up `Geo::EventWorker` S->>TDB: Insert to `job_artifact_registry`, "starting sync" S->>PP: GET <primary site internal URL>/geo/retrieve/job_artifact/123 S->>TDB: Update `job_artifact_registry`, "synced"
- Geo Log Cursor 循环找到新的
geo_event_log行 - Geo Log Cursor 处理
geo_events行- Geo Log Cursor 排队
Geo::EventWorker作业,传递geo_events行数据
- Geo Log Cursor 排队
- Sidekiq 拾取
Geo::EventWorker作业- Sidekiq 在 PostgreSQL Geo Tracking Database 中插入
job_artifact_registry行(因为尚不存在),并将其标记为"开始同步" - Sidekiq 对主 Geo 站点的 API 端点执行 GET 请求并下载文件
- Sidekiq 将
job_artifact_registry行标记为"已同步"和"等待验证"
- Sidekiq 在 PostgreSQL Geo Tracking Database 中插入
填充现有的作业工件
- 系统管理员有一个没有 Geo 的现有 GitLab 站点
- 存在现有的 CI 作业和作业工件
- 系统管理员设置一个新的 GitLab 站点并将其配置为 secondary Geo 站点
Secondary 站点:
有两个每分钟运行的 cronjob:Geo::Secondary::RegistryConsistencyWorker 和 Geo::RegistrySyncWorker。下面的工作流程分为两部分,对应这两个 cronjob。
sequenceDiagram participant SC as Sidekiq-cron participant R as Redis participant S as Sidekiq participant DB as PostgreSQL participant TDB as PostgreSQL Tracking DB SC->>R: Enqueue `Geo::Secondary::RegistryConsistencyWorker` S->>R: Pick up `Geo::Secondary::RegistryConsistencyWorker` S->>DB: Query `ci_job_artifacts` S->>TDB: Query `job_artifact_registry` S->>TDB: Insert to `job_artifact_registry`
- Sidekiq-cron 每分钟排入一个
Geo::Secondary::RegistryConsistencyWorker作业。只要它正在积极工作(创建和删除行),该作业会立即重新排入自身。此作业使用独占租约来防止多个实例同时运行。 - Sidekiq 拾取
Geo::Secondary::RegistryConsistencyWorker作业- Sidekiq 查询
ci_job_artifacts表,最多 10000 行 - Sidekiq 查询
job_artifact_registry表,最多 10000 行 - Sidekiq 在 PostgreSQL Geo Tracking Database 中插入一个
job_artifact_registry行,对应现有的作业工件
- Sidekiq 查询
sequenceDiagram participant SC as Sidekiq-cron participant R as Redis participant S as Sidekiq participant DB as PostgreSQL participant TDB as PostgreSQL Tracking DB participant PP as Primary site Puma SC->>R: Enqueue `Geo::RegistrySyncWorker` S->>R: Pick up `Geo::RegistrySyncWorker` S->>TDB: Query `*_registry` tables S->>R: Enqueue `Geo::EventWorker`s S->>R: Pick up `Geo::EventWorker` S->>TDB: Insert to `job_artifact_registry`, "starting sync" S->>PP: GET <primary site internal URL>/geo/retrieve/job_artifact/123 S->>TDB: Update `job_artifact_registry`, "synced"
- Sidekiq-cron 每分钟排入一个
Geo::RegistrySyncWorker作业。只要它正在积极工作,该作业会循环最多一小时来调度同步作业。此作业使用独占租约来防止多个实例同时运行。 - Sidekiq 拾取
Geo::RegistrySyncWorker作业- Sidekiq 查询 PostgreSQL Geo Tracking Database 中所有
registry表的"从未尝试同步"行。它交错来自每个表的行并将它们添加到内存队列中。 - 如果上一步产生的行少于 1000 行,则 Sidekiq 查询所有
registry表中"同步失败且准备重试"的行,交错这些行并将它们添加到内存队列中。 - Sidekiq 为队列中的每个项目排入
Geo::EventWorker作业,参数如"ID 为 123 的作业工件已更新",并跟踪排入的 Sidekiq 作业 ID。 - 当达到"最大并发限制"设置时,Sidekiq 停止排入
Geo::EventWorker作业 - Sidekiq 循环执行此类工作,直到没有更多工作要做
- Sidekiq 查询 PostgreSQL Geo Tracking Database 中所有
- Sidekiq 拾取
Geo::EventWorker作业- Sidekiq 将
job_artifact_registry行标记为"开始同步" - Sidekiq 对主 Geo 站点的 API 端点执行 GET 请求并下载文件
- Sidekiq 将
job_artifact_registry行标记为"已同步"和"等待验证"
- Sidekiq 将
验证新的作业工件
Primary 站点:
sequenceDiagram participant Ru as Runner participant P as Puma participant DB as PostgreSQL participant SC as Sidekiq-cron participant Rd as Redis participant S as Sidekiq participant F as Filesystem Ru->>P: Upload artifact P->>DB: Insert `ci_job_artifacts` P->>DB: Insert `ci_job_artifact_states` SC->>Rd: Enqueue `Geo::VerificationCronWorker` S->>Rd: Pick up `Geo::VerificationCronWorker` S->>DB: Query `ci_job_artifact_states` S->>Rd: Enqueue `Geo::VerificationBatchWorker` S->>Rd: Pick up `Geo::VerificationBatchWorker` S->>DB: Query `ci_job_artifact_states` S->>DB: Update `ci_job_artifact_states` row, "started" S->>F: Checksum file S->>DB: Update `ci_job_artifact_states` row, "succeeded"
- Runner 上传一个工件
- Puma 创建一个
ci_job_artifacts行 - Puma 创建一个
ci_job_artifact_states行来存储验证状态。- 该行被标记为"等待验证"
- Sidekiq-cron 每分钟排入一个
Geo::VerificationCronWorker作业 - Sidekiq 拾取
Geo::VerificationCronWorker作业- Sidekiq 查询
ci_job_artifact_states中标记为"等待验证"或"验证失败且准备重试"的行数 - Sidekiq 排入一个或多个
Geo::VerificationBatchWorker作业,受"最大验证并发"设置限制
- Sidekiq 查询
- Sidekiq 拾取
Geo::VerificationBatchWorker作业- Sidekiq 查询
ci_job_artifact_states中标记为"等待验证"的行 - 如果上一步产生的行少于 10 行,则 Sidekiq 查询
ci_job_artifact_states中标记为"验证失败且准备重试"的行 - 对于每一行
- Sidekiq 将其标记为"开始验证"
- Sidekiq 获取文件的 SHA256 校验和
- Sidekiq 将校验和保存在行中并将其标记为"验证成功"
- 现在 secondary Geo 站点可以与此校验和进行比较
- Sidekiq 查询
Secondary 站点:
sequenceDiagram participant SC as Sidekiq-cron participant R as Redis participant S as Sidekiq participant TDB as PostgreSQL Tracking DB participant F as Filesystem participant DB as PostgreSQL SC->>R: Enqueue `Geo::VerificationCronWorker` S->>R: Pick up `Geo::VerificationCronWorker` S->>TDB: Query `job_artifact_registry` S->>R: Enqueue `Geo::VerificationBatchWorker` S->>R: Pick up `Geo::VerificationBatchWorker` S->>TDB: Query `job_artifact_registry` S->>TDB: Update `job_artifact_registry` row, "started" S->>F: Checksum file S->>DB: Query `ci_job_artifact_states` S->>TDB: Update `job_artifact_registry` row, "succeeded"
- 工件成功同步后,它变为"等待验证"
- Sidekiq-cron 每分钟排入一个
Geo::VerificationCronWorker作业 - Sidekiq 拾取
Geo::VerificationCronWorker作业- Sidekiq 查询 PostgreSQL Geo Tracking Database 中标记为"等待验证"或"验证失败且准备重试"的行数
- Sidekiq 排入一个或多个
Geo::VerificationBatchWorker作业,受"最大验证并发"设置限制
- Sidekiq 拾取
Geo::VerificationBatchWorker作业- Sidekiq 查询 PostgreSQL Geo Tracking Database 中标记为"等待验证"的
job_artifact_registry行 - 如果上一步产生的行少于 10 行,则 Sidekiq 查询
job_artifact_registry中标记为"验证失败且准备重试"的行 - 对于每一行
- Sidekiq 将其标记为"开始验证"
- Sidekiq 获取文件的 SHA256 校验和
- Sidekiq 将校验和保存在行中
- Sidekiq 将校验和与 PostgreSQL 复制的
ci_job_artifact_states行中的校验和进行比较 - 如果校验和匹配,则 Sidekiq 将
job_artifact_registry行标记为"验证成功"
- Sidekiq 查询 PostgreSQL Geo Tracking Database 中标记为"等待验证"的
身份验证
为了验证 Git 和文件传输,每个 GeoNode 记录有两个字段:
- 公钥(
access_key字段)。 - 私钥(
secret_access_key字段)。
secondary 站点通过 JWT 请求 进行身份验证。
secondary 站点使用 Authorization 标头授权 HTTP 请求:
Authorization: GL-Geo <access_key>:<JWT payload>primary 站点使用 access_key 字段查找对应的 secondary 站点并解密 JWT 载荷。
JWT 要求涉及的机器时钟同步,否则 primary 站点可能会拒绝请求。
文件传输
当 secondary 站点希望下载文件时,JWT 载荷包含额外的信息来标识文件请求。这确保 secondary 站点为正确的数据库 ID 下载正确的文件。例如,对于 LFS 对象,请求还必须包含文件的 SHA256 总和。示例 JWT 载荷如下:
{"data": {"sha256": "31806bb23580caab78040f8c45d329f5016b0115"}, "iat": "1234567890"}如果请求的文件与请求的 SHA256 总和匹配,则 Geo primary 站点通过 X-Sendfile 功能发送数据,该功能允许 NGINX 处理文件传输而不会占用 Rails 或 Workhorse。
Git 传输
当 secondary 站点希望从 primary 站点克隆或获取 Git 仓库时,JWT 载荷包含额外的信息来标识 Git 仓库请求。这确保 secondary 站点为正确的数据库 ID 下载正确的 Git 仓库。示例 JWT 载荷如下:
{"data": {"scope": "mygroup/myproject"}, "iat": "1234567890"}向 Geo secondary 推送 Git
Git Push Proxy 作为 gitlab-shell 组件内的功能存在。它仅在 secondary 站点上激活。它允许从 secondary 站点克隆仓库的用户推送到相同的 URL。
发送到 secondary 站点的 Git push 请求将被发送到 primary 站点,而 pull 请求将继续由 secondary 站点提供服务,以实现最大效率。
HTTPS 和 SSH 请求的处理方式不同:
- 对于 HTTPS,我们将给用户一个指向 primary 站点上项目的
HTTP 302 Redirect。Git 客户端足够智能,可以理解该状态代码并处理重定向。 - 对于 SSH,因为没有等效的重定向方式,我们必须代理该请求。这是在
gitlab-shell中完成的,首先将请求转换为 HTTP 协议,然后将其代理到 primary 站点。
gitlab-shell 守护进程根据 /api/v4/allowed 的响应知道何时进行代理。返回特殊的 HTTP 300 状态代码,我们执行响应体中指定的"自定义操作"。响应包含额外的数据,使得代理的 push 操作能够在 primary 站点上发生。
使用跟踪数据库
除了被复制的主数据库外,Geo secondary 站点有自己的独立 Tracking database。
跟踪数据库包含 secondary 站点的状态。
任何需要作为升级一部分运行的数据库迁移都需要在每个 secondary 站点上应用于跟踪数据库。
配置
数据库配置在 config/database.yml 中设置。目录 ee/db/geo 包含该数据库的架构和迁移。
要为数据库编写迁移,请运行:
rails g migration [args] [options] --database geo要迁移跟踪数据库,请运行:
bundle exec rake db:migrate:geo查找器
Geo 使用 Finders,这些类负责在跟踪数据库和主数据库中查找项目/附件等繁重的工作。
Redis
secondary 站点上的 Redis 与 primary 站点上的工作方式相同。它用于缓存、存储会话和其他持久数据。
primary 和 secondary 站点之间的 Redis 数据复制不被使用,因此会话等数据不会在站点之间共享。
对象存储
GitLab 可以选择使用对象存储来存储原本存储在磁盘上的数据。例如:
- LFS 对象
- CI 作业工件
- 上传
默认情况下,Geo 不复制存储在对象存储中的对象。根据客户的情况和需求,他们可以:
- 启用 GitLab 管理的对象存储复制。
- 使用其云提供商的内置服务在 Geo 站点之间复制对象存储。
- 将 secondary Geo 站点配置为访问与 primary 站点相同的对象存储端点。
验证
验证状态
下图说明了验证的工作原理。为清晰起见,省略了一些允许的转换。
stateDiagram-v2
Pending --> Started
Pending --> Disabled: No primary checksum
Disabled --> Started: Primary checksum succeeded
Started --> Succeeded
Started --> Failed
Succeeded --> Pending: Mark for reverify
Failed --> Pending: Mark for reverify
Failed --> Started: Retry
仓库验证
仓库使用校验和进行验证。
primary 站点计算仓库的校验和。它基本上将所有 Git refs 一起哈希,并将该哈希存储在数据库的 project_repository_states 表中。
secondary 站点执行相同的操作来计算其克隆的哈希,并将该哈希与 primary 站点计算的值进行比较。如果不匹配,Geo 将将其标记为不匹配,管理员可以在 Geo Admin 区域 中看到此情况。
Geo 代理
Geo secondaries 可以将 Web 请求代理到 primary。 更多内容请参阅 Geo 代理 (development) 页面。
Geo API
Geo 使用外部 API 来促进各种组件之间的通信。
术语表
Primary 站点
primary 站点是 Geo 设置中具有读写能力的单个站点。它是单一的事实来源,Geo secondary 站点从那里复制其数据。
在 Geo 设置中,只能有一个 primary 站点。所有 secondary 站点都连接到该 primary。
Secondary 站点
secondary 站点是运行在不同地理位置的 primary 站点的只读副本。
流式复制
Geo 依赖于 PostgreSQL 的流式复制功能。它完全复制数据库数据和数据库架构。数据库副本是只读副本。
流式复制依赖于预写日志(WAL)。这些日志被复制到副本并在那里重放。
由于流式复制还复制架构,因此数据库迁移不需要在 secondary 站点上运行。
跟踪数据库
每个 Geo secondary 站点上的数据库,用于保存其所在站点的状态。更多内容请参阅 使用跟踪数据库。
Geo 事件日志
Geo primary 将事件存储在 geo_event_log 表中。日志中的每个条目都包含特定类型的事件。这些类型的事件包括:
- 仓库删除事件
- 仓库重命名事件
- 仓库变更事件
- 仓库创建事件
- 哈希存储迁移事件
- LFS 对象删除事件
- 哈希存储附件事件
- 作业工件删除事件
- 上传删除事件
请参阅 Geo Log Cursor 守护进程。
代码特性
Gitlab::Geo 工具
与 Geo 相关的小型工具方法放入 ee/lib/gitlab/geo.rb 文件中。
许多这些方法使用 RequestStore 类进行缓存,以减少在整个代码库中使用这些方法对性能的影响。
当前站点
类方法 .current_node 返回当前站点的 GeoNode 记录。
我们使用 gitlab.yml 中的 host、port 和 relative_url_root 值,并在数据库中搜索以识别我们在哪个站点(参见 GeoNode.current_node)。
Primary 或 Secondary
要确定当前站点是 primary 站点还是 secondary 站点,请使用 .primary? 和 .secondary? 类方法。
当站点未启用时,这些方法都可能在一个站点上返回 false。请参阅 启用。
Geo 数据库已配置?
在处理初始化时间发生的事情时,还有一个额外的注意事项。在少数地方,我们使用 Gitlab::Geo.geo_database_configured? 方法来检查站点是否有跟踪数据库,该数据库仅存在于 secondary 站点。这克服了在新站点引导过程中可能发生的竞争条件。
启用
当用户拥有包含该功能的许可证,并且在 Geo Nodes 屏幕上至少定义了一个站点时,我们认为 Geo 功能已启用。
请参阅 Gitlab::Geo.enabled? 和 Gitlab::Geo.license_allows? 方法。
只读
所有 Geo secondary 站点都是只读的。
只读数据库 的通用原则适用于所有 Geo secondary 站点。因此 Gitlab::Database.read_only? 方法在 secondary 站点上将始终返回 true。
当某些写入操作因为站点是 secondary 而不被允许时,考虑添加 Gitlab::Database.read_only? 或 Gitlab::Database.read_write? 守卫,而不是 Gitlab::Geo.secondary?。
数据库本身在复制设置中已经是只读的,所以我们不需要为此采取任何额外步骤。
确保新功能具有 Geo 支持
Geo 依赖于主数据库和 CI 数据库的 PostgreSQL 复制,因此如果您添加新表或字段,它应该已经在 secondary Geo 站点上工作。
但是,如果您引入了一种新的数据类型,这些数据存储在主 PostgreSQL 数据库和 CI PostgreSQL 数据库之外,那么您需要确保这些数据被 Geo 复制和验证。这对于客户能够依靠其 secondary 站点进行 灾难恢复 是必要的。
以下小节描述了如何确定是否需要工作,以及如果需要,如何进行。如果您有任何问题,联系 Geo 团队。
要与您自己的功能进行比较,请参阅 支持的 Geo 数据类型。它有 Geo 复制和验证的数据类型的详细、最新列表。
Git 仓库
如果您添加了由 Git 仓库支持的功能,那么您必须添加 Geo 支持。请参阅 Geo 自助服务框架的仓库复制器策略。
基于 Geo 复制新的 blob 类型模板 创建问题并遵循指南。
Blobs
如果您添加了 CarrierWave::Uploader::Base 的子类,那么您正在添加 Geo 称为 blob 的内容。如果您特别按照通常推荐的子类化 AttachmentUploader,那么数据已经具有 Geo 支持,无需额外工作。这是因为 AttachmentUploader 使用 Upload 模型和 uploads 表跟踪 blob,并且该模型已经实现了 Geo 支持。
如果您的 blob 在新表中跟踪,也许是因为您预计在 GitLab.com 规模下会有数百万行,那么您必须添加 Geo 支持。请参阅 Geo 自助服务框架的 blob 复制器策略。
Geo 通过一个规范检测新的 blob,当 Uploader 没有对应的 Replicator 时该规范会失败。
基于 Geo 复制新的 Git 仓库类型模板 创建问题并遵循指南。
具有多种数据的功能
如果一个新的复杂功能由多种数据支持,例如,一个 Git 仓库和一个 blob,那么您可能可以分别考虑每种数据类型。
以 Designs 为例,每个问题都有一个 Git 仓库,它可以有许多 LFS 对象,每个 LFS 对象可能有一个自动生成的缩略图。
- LFS 对象已经由 Geo 支持,因此不需要特定的 Geo 工作。
- 缩略图的实现重用了
Upload模型,因此不需要特定的 Geo 工作。 - Design Git 仓库本身不受 Geo 支持,因此需要工作。
另一个例子是 Dependency Proxy,它由两种类型的 blob 支持:DependencyProxy::Blob 和 DependencyProxy::Manifest。我们可以在每种类型上独立使用 Geo 自助服务框架的 blob 复制器策略。
其他类型的数据
如果您的新功能引入了一种新的数据类型,它不是 Git 仓库、blob 或两者的组合,那么请联系 Geo 团队讨论如何处理。
例如,容器注册表数据不容易适合上述类别。它由拥有数据的注册表服务支持,GitLab 与注册表服务的 API 交互。因此,容器注册表的 Geo 支持需要一次性方法。尽管如此,我们仍然能够重用 Geo 自助服务框架 的许多粘合代码。
自助服务框架
如果您想为您正在处理的功能添加简单的 Geo 复制,请查看我们的 自助服务框架。
Geo 开发工作流
GET:Geo 管道
在触发成功的 e2e:test-on-omnibus-ee 管道后,您可以手动触发一个名为 GET:Geo 的作业:
- 在 GitLab 项目 中,选择合并请求的 Pipelines 选项卡。
- 选择最新管道的
Stage: qa阶段以展开并列出所有相关作业。 - 选择触发作业
e2e:test-on-omnibus-ee以导航到子管道。 - 选择
trigger-omnibus以查看与合并请求对应的 Omnibus GitLab Mirror 管道。 GET:Geo作业可以在trigger-qa阶段找到并触发。
此管道使用 GET 创建一个 20 RPS / 1k users Geo 安装,并针对该实例运行 gitlab-qa Geo 场景。在处理 Geo 功能时,确保在触发的 GET:Geo 管道中 qa-geo 作业通过是个好主意。
控制实例预配和拆除的管道包含在 GitLab 环境工具包配置的 Geo 子项目 中。
添加新功能时,考虑添加新测试来验证行为。有关步骤,请参阅 QA 文档。
架构
该管道涉及多个不同项目的交互:
- GitLab -
e2e:test-on-omnibus-ee作业 从此项目的合并请求中启动。 omnibus-gitlab- 构建包含来自触发合并请求管道更改的相关工件。- GET-Configs/Geo - 协调可评估的短暂 Geo 安装的生命周期。
- GET - 包含创建和销毁 Geo 安装所需的逻辑。由
GET-Configs/Geo使用。 gitlab-qa- 用于针对 GitLab 实例运行自动化测试的工具。
flowchart TD;
GET:Geo-->getcg
Provision-->Terraform
Configure-->Ansible
Geo-->Ansible
QA-->gagq
subgraph "omnibus-gitlab-mirror"
GET:Geo
end
subgraph getcg [GitLab-environment-toolkit-configs/Geo]
direction LR
Generate-terraform-config-->Provision
Provision-->Generate-ansible-config
Generate-ansible-config-->Configure
Configure-->Geo
Geo-->QA
QA-->Destroy-geo
end
subgraph get [GitLab Environment Toolkit]
Terraform
Ansible
end
subgraph GitLab QA
gagq[GitLab QA Geo Scenario]
end